Feature engineering
Feature 는 측량된 값, Column 을 말합니다.

Feature engineering 이란 데이터 컬럼을 생성하거나 선택하는 작업, 주어진 초기 데이터로부터 특징을 가공하고 생성하는 전체 과정을 의미합니다.
거의 모든 머신러닝 Classifier 는 숫자 데이터를 사용하기 때문에 Feature engineering 을 통해 텍스트 데이터는 숫자 데이터로 만들어 Feature Vector 로 구성해주고, 결측 데이터(NaN)도 알맞은 값으로 넣어주는 작업을 해보겠습니다.
Name 컬럼을 보면 호칭 정보가 있습니다.
Ms 성인 여성, Miss 미혼 여성, Mrs 기혼 여성, Mr 남성 등
이러한 정보를 Title 컬럼으로 빼내고 맵핑을 해주었습니다.

train_test_data = [train, test]
for dataset in train_test_data:
dataset['Title'] = dataset['Name'].str.extract('([A-Za-z]+)\.', expand=False)title_mapping = {"Mr": 0, "Miss": 1, "Mrs": 2,
"Master": 3, "Dr": 3, "Rev": 3, "Col": 3, "Major": 3, "Mlle": 3, "Countess": 3,
"Ms": 3, "Lady": 3, "Jonkheer": 3, "Don": 3, "Dona": 3, "Mme":3, "Capt": 3, "Sir": 3 }
for dataset in train_test_data:
dataset['Title'] = dataset['Title'].map(title_mapping)
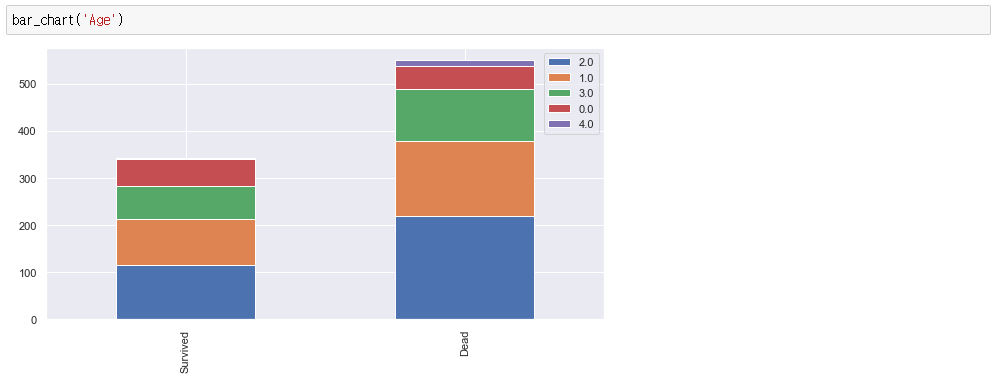
0 은 남성으로 확연한 차이를 보이고 있습니다.

호칭 정보를 빼냈으므로 Name 컬럼은 삭제합니다.
train.drop('Name', axis=1, inplace=True)
test.drop('Name', axis=1, inplace=True)
Sex 컬럼은 단순히 숫자 데이터로 맵핑해줍니다.
sex_mapping = {'male': 0, 'female': 1}
for dataset in train_test_data:
dataset['Sex'] = dataset['Sex'].map(sex_mapping)
Age 컬럼은 결측 데이터가 많습니다.
위에서 얻은 Title 컬럼의 정보를 사용하여 나이를 채우려고 합니다.

Age 컬럼의 데이터가 NA 이면 타이틀별 평균값으로 대체합니다.
train["Age"].fillna(train.groupby("Title")["Age"].transform("median"), inplace=True)
test["Age"].fillna(test.groupby("Title")["Age"].transform("median"), inplace=True)
Sequential 한 정보가 별로 효과적이지 않을 경우, Feature engineering 의 Binning 기술을 이용해서 범위를 묶어서 카테고리로 분류하여 적용할 수 있습니다.
다음과 같이 Age 컬럼에 대해서 나이대를 묶어서 카테고리로 분류합니다.
for dataset in train_test_data:
dataset.loc[ dataset['Age'] <= 16, 'Age'] = 0
dataset.loc[(dataset['Age'] > 16) & (dataset['Age'] <= 26), 'Age' ] = 1
dataset.loc[(dataset['Age'] > 26) & (dataset['Age'] <= 36), 'Age' ] = 2
dataset.loc[(dataset['Age'] > 36) & (dataset['Age'] <= 62), 'Age' ] = 3
dataset.loc[ dataset['Age'] > 62, 'Age'] = 4
다음으로 Embarked 컬럼을 살펴보면, Q 선박장을 통해 승선한 승객은 거의 3등급이고 S 선박장에서 승선한 승객의 비율은 모든 등급에서 5~60% 이상이므로 Embarked 데이터가 NA 라면 S 라고 넣어주어도 무방하다고 볼 수 있습니다.
Pclass1 = train[train['Pclass']==1]['Embarked'].value_counts()
Pclass2 = train[train['Pclass']==2]['Embarked'].value_counts()
Pclass3 = train[train['Pclass']==3]['Embarked'].value_counts()
df = pd.DataFrame([Pclass1, Pclass2, Pclass3])
df.index = [ '1st class', '2nd class', '3nd class' ]
df.plot(kind='bar', stacked=True, figsize=(10, 5))for dataset in train_test_data:
dataset['Embarked'] = dataset['Embarked'].fillna('S')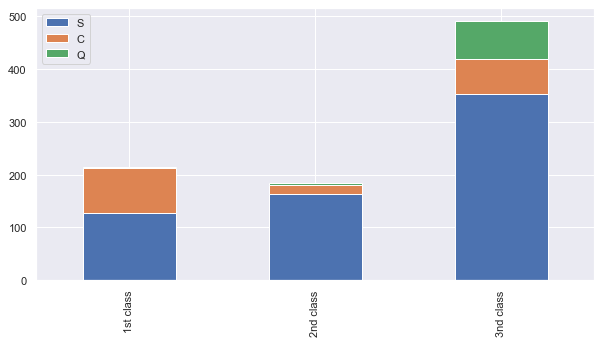
그리고 숫자 데이터로 맵핑합니다.
embarked_mapping = {'S': 0, 'C': 1, 'Q': 2}
for dataset in train_test_data:
dataset['Embarked'] = dataset['Embarked'].map(embarked_mapping)
다음은 Fare 컬럼입니다.
Fare 컬럼은 Pclass 와 관계가 있습니다. 이를 이용하여 Pclass 의 NA 데이터를 채워줍니다.
train['Fare'].fillna(train.groupby('Pclass')['Fare'].transform('median'), inplace=True)
test['Fare'].fillna(test.groupby('Pclass')['Fare'].transform('median'), inplace=True)
이 또한 Binning 기술을 이용해서 카테고리로 분류합니다.
for dataset in train_test_data:
dataset.loc[ dataset['Fare'] <= 17, 'Fare'] = 0
dataset.loc[(dataset['Fare'] > 17) & (dataset['Fare'] <= 30), 'Fare' ] = 1
dataset.loc[(dataset['Fare'] > 30) & (dataset['Fare'] <= 100), 'Fare' ] = 2
dataset.loc[ dataset['Fare'] > 100, 'Fare'] = 3
다음은 Cabin 컬럼으로 객실 번호를 나타냅니다.
첫 번째 알파벳만을 가져와서 비교해봅니다.

for dataset in train_test_data:
dataset['Cabin'] = dataset['Cabin'].str[:1]
Pclass1 = train[train['Pclass']==1]['Cabin'].value_counts()
Pclass2 = train[train['Pclass']==2]['Cabin'].value_counts()
Pclass3 = train[train['Pclass']==3]['Cabin'].value_counts()
df = pd.DataFrame([Pclass1, Pclass2, Pclass3])
df.index = [ '1st class', '2nd class', '3nd class' ]
df.plot(kind='bar', stacked=True, figsize=(10, 5))
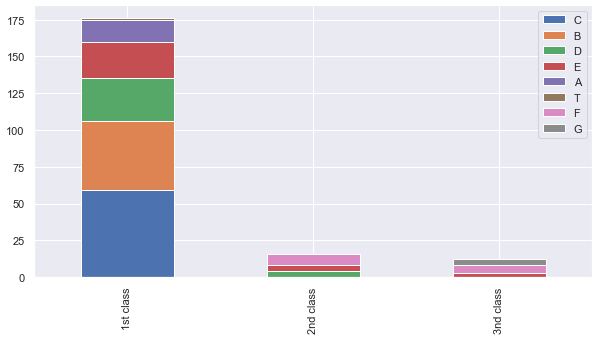
알파벳 CBDEA 로 시작하는 객실은 2등급과 3등급에는 거의 없는 것을 볼 수 있습니다.
또한 숫자 데이터로 맵핑합니다.
여기서 소수점을 사용했는데, 이것을 Feature scaling 이라고 합니다.
기본적으로 머신러닝 Classifier 는 숫자를 사용하고 계산을 할 때 유클리디안 디스턴스를 사용하는데, 숫자의 범위가 비슷하지 않으면, 큰 거리를 좀 더 비중있게 봅니다.
예를들면 중요한 Sex 컬럼의 남자와 여자의 차이는 1-0 으로 1 이고, 별로 중요하지 않은 Fare 컬럼의 10달러 티켓과 20달러 티켓 차이를 더 비중있게 봅니다.
따라서 소수로 나누어서 맵핑해 주었습니다.
cabin_mapping = {'A': 0, 'B': 0.4, 'C': 0.8, 'D': 1.2, 'E': 1.6, 'F': 2, 'G': 2.4, 'T': 2.8}
for dataset in train_test_data:
dataset['Cabin'] = dataset['Cabin'].map(cabin_mapping)
그리고 객실번호는 각 클래스와 관련이 있기 때문에 NA 값을 넣어줍니다.
train['Cabin'].fillna(train.groupby('Pclass')['Cabin'].transform('median'), inplace=True)
test['Cabin'].fillna(train.groupby('Pclass')['Cabin'].transform('median'), inplace=True)
다음은 SibSp 컬럼과 Parch 컬럼입니다.
동승한 형제 수와 부모의 수는 비슷한 유형이어서 FamilySize 컬럼으로 합처주었습니다.
train["FamilySize"] = train["SibSp"] + train["Parch"] + 1
test["FamilySize"] = test["SibSp"] + test["Parch"] + 1
이 또한 Feature scaling 으로 맵핑합니다.
family_mapping = {1: 0, 2: 0.4, 3: 0.8, 4: 1.2, 5: 1.6, 6: 2, 7: 2.4, 8: 2.8, 9: 3.2, 10: 3.6, 11: 4}
for dataset in train_test_data:
dataset['FamilySize'] = dataset['FamilySize'].map(family_mapping)
이제 데이터를 확인해보면 Feature Vector 로만 구성된 Array 가 되었습니다.
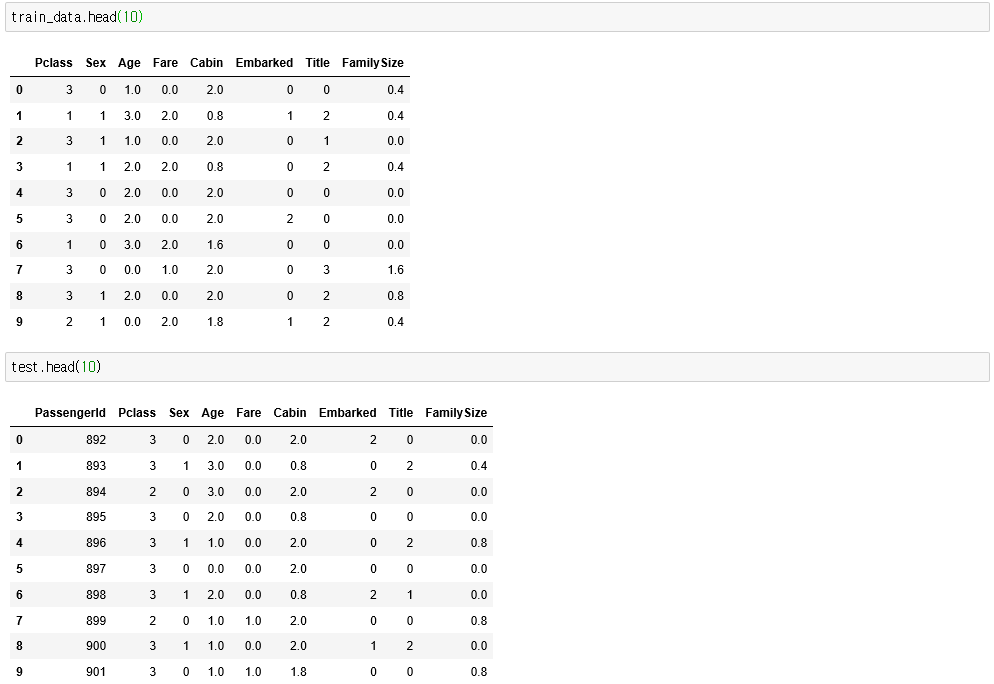
참고
'AI > ML' 카테고리의 다른 글
| 캐글(Kaggle) 자전거 수요 예측 -1 (0) | 2020.08.23 |
|---|---|
| 캐글(Kaggle) 타이타닉 생존자 예측하기 -3 (0) | 2020.08.22 |
| 캐글(Kaggle) 타이타닉 생존자 예측하기 -1 (0) | 2020.08.22 |