데이터 다운로드
아래 링크에 데이터셋을 다운로드할 수 있습니다.
Bike Sharing Demand
Forecast use of a city bikeshare system
www.kaggle.com
데이터 분석
데이터를 확인합니다.
Train data 는 10886 개의 행, 12 개의 컬럼을 가지고 있고, Test data 는 6493 개의 행, 9 개의 컬럼을 가지고 있습니다.

결측 데이터는 없습니다.
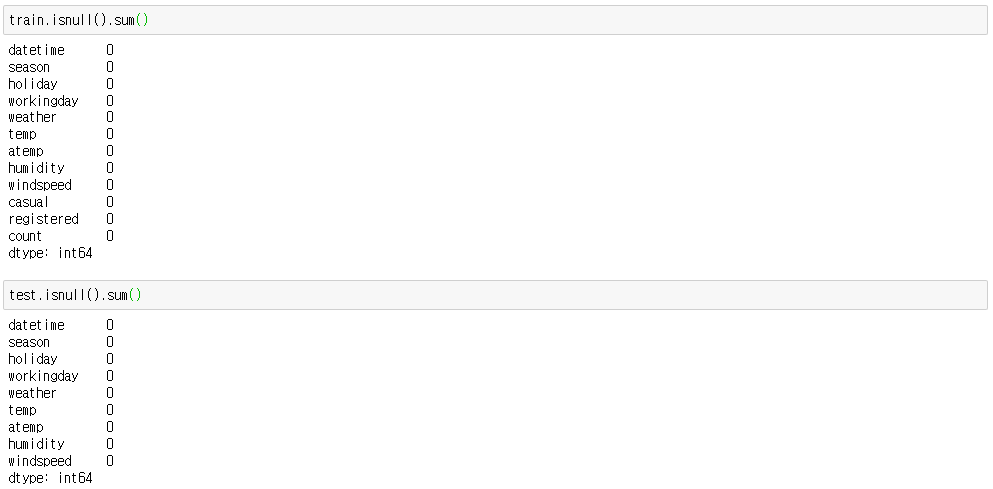
결측치를 시각화해주는 missingno 모듈을 사용

출/퇴근 시간대의 따라 자전거 수요량을 비교해 보기위해 datetime 컬럼을 나누어 봅니다.
train['year'] = train['datetime'].dt.year
train['month'] = train['datetime'].dt.month
train['day'] = train['datetime'].dt.day
train['hour'] = train['datetime'].dt.hour
train['minute'] = train['datetime'].dt.minute
train['second'] = train['datetime'].dt.second
train.shape(10886, 18)
그래프로 확인합니다.
figure, ((ax1, ax2, ax3), (ax4, ax5, ax6)) = plt.subplots(nrows=2, ncols=3)
figure.set_size_inches(18, 8)
sns.barplot(data=train, x='year', y='count', ax=ax1)
sns.barplot(data=train, x='month', y='count', ax=ax2)
sns.barplot(data=train, x='day', y='count', ax=ax3)
sns.barplot(data=train, x='hour', y='count', ax=ax4)
sns.barplot(data=train, x='minute', y='count', ax=ax5)
sns.barplot(data=train, x='second', y='count', ax=ax6)
ax1.set(ylabel='Count', title='연도별 대여량')
ax2.set(ylabel='month', title='월별 대여량')
ax3.set(ylabel='day', title='일별 대여량')
ax4.set(ylabel='hour', title='시간별 대여량')
각 그래프를 보면 2012년에 수요가 상당히 증가했고, 날씨가 따뜻한 월과 출퇴근 시간에 수요가 많은 것을 보실 수 있습니다.
day 컬럼을 보면 Train data 에서는 1~19일 까지의 범위를 가지는데 Test data 는 19일 이후 부터의 범위를 가지므로 피처로 사용하기에는 무리가 있어보이고, minute, second 컬럼은 전부 0의 값을 가집니다.

다른 컬럼들도 비교해봅니다.
season 컬럼은 (0: 봄, 1: 여름, 2: 가을, 3: 겨울) 의 범위를 가지고
workingday 컬럼은 (0: 휴일, 1: 근무) 의 범위를 가집니다.
fig, axes = plt.subplots(nrows=2,ncols=2)
fig.set_size_inches(12, 10)
sns.boxplot(data=train,y="count",orient="v",ax=axes[0][0])
sns.boxplot(data=train,y="count",x="season",orient="v",ax=axes[0][1])
sns.boxplot(data=train,y="count",x="hour",orient="v",ax=axes[1][0])
sns.boxplot(data=train,y="count",x="workingday",orient="v",ax=axes[1][1])
axes[0][0].set(ylabel='Count',title="대여량")
axes[0][1].set(xlabel='Season', ylabel='Count',title="계절별 대여량")
axes[1][0].set(xlabel='Hour Of The Day', ylabel='Count',title="시간별 대여량")
axes[1][1].set(xlabel='Working Day', ylabel='Count',title="근무일 여부에 따른 대여량")
그래프를 보면 여름, 가을에 좀 더 수요량이 많고, 근무일보다 휴일에 조금 더 수요량이 많습니다.

pointplot 을 이용해서 좀더 살펴보도록 하겠습니다.
x 축에는 hour 컬럼을 주었습니다.
fig,(ax,ax2)= plt.subplots(nrows=2)
fig.set_size_inches(18,15)
sns.pointplot(data=train, x="hour", y="count", hue="workingday", ax=ax)
sns.pointplot(data=train, x="hour", y="count", hue="dayofweek", ax=ax2)
workingday 컬럼에 대한 첫 번째 그래프로 근무일에는 출퇴근 시간에 대여량이 많고, 휴일에는 늦은 오전부터 점심 시간대에 대여량이 높은 것을 볼 수 있습니다.
dayofweek 컬럼에 대한 두 번째 그래프에서는 첫 번째 그래프(1)와 동일한 모양을 하고 있는 0-4 은 근무일로 5-6 은 휴일인 것을 볼 수 있습니다.

다음은 weather 컬럼과 season 컬럼에 대한 그래프를 보겠습니다.
weather 컬럼은 (1: 좋음, 2: 보통, 3: 안좋음, 4: 눈/비) 의 범위를 가집니다.
fig,(ax,ax2)= plt.subplots(nrows=2)
fig.set_size_inches(18,15)
sns.pointplot(data=train, x="hour", y="count", hue="weather", ax=ax)
sns.pointplot(data=train, x="hour", y="count", hue="season", ax=ax2)
날씨가 매우 안좋을 경우에는 대여량의 거의 없습니다.
계절의 경우에는 위에서 보셨던거와 동일하게 여름, 가을, 겨울, 봄 순으로 대여량이 높았습니다.

다음은 대여량과 나머지 컬럼들에 대한 관계를 알아보기 위해 heatmap 으로 그려봅니다.
corrMatt = train[['temp', 'atemp', 'casual', 'registered', 'humidity', 'windspeed', 'count']]
corrMatt = corrMatt.corr()
print(corrMatt)
mask = np.array(corrMatt)
mask[np.tril_indices_from(mask)] = False
fig, ax = plt.subplots()
fig.set_size_inches(20, 10)
sns.heatmap(corrMatt, mask=mask, vmax=.8, square=True, annot=True)
온도와 습도는 대여량과 연관이 거의없으며, registered 컬럼이 관계가 가장 큰 것으로 나타났습니다.
casual 컬럼은 등록되지 않은 사용자, registered 컬럼은 등록된 사용자입니다.
하지만 Test data 에는 없는 컬럼이기 때문에 피처로 사용하기에는 어려울 것 같습니다.

windspeed 컬럼을 보면 0 인 데이터가 굉장히 많으며, 이 부분은 Feature engineering 을 통해 적절한 값을 넣어주면 될 것 같습니다.
fig, (ax1, ax2, ax3) = plt.subplots(ncols=3)
fig.set_size_inches(12, 5)
sns.regplot(x='temp', y='count', data=train, ax=ax1)
sns.regplot(x='windspeed', y='count', data=train, ax=ax2)
sns.regplot(x='humidity', y='count', data=train, ax=ax3)

참고
'AI > ML' 카테고리의 다른 글
| 캐글(Kaggle) 타이타닉 생존자 예측하기 -3 (0) | 2020.08.22 |
|---|---|
| 캐글(Kaggle) 타이타닉 생존자 예측하기 -2 (0) | 2020.08.22 |
| 캐글(Kaggle) 타이타닉 생존자 예측하기 -1 (0) | 2020.08.22 |